
The purpose of tracking
 Thomas Ghys
Thomas Ghys
Tracking gets a bad rep. European data protection authorities label tracking as an act of surveillance. When your device is fingerprinted for ad retargeting, that label is appropriate. But not all tracking works that way. Most tracking you come across isn’t very intrusive and can improve your online experience.
In article Why Trackers eat cookies for breakfast, I explained how cookies support tracking. In this follow-up article, I dig deeper into how you can interpret trackers and assess their intrusiveness objectively.
This piece is written with privacy professionals in mind, charged with auditing websites or mobile applications, but anyone curious about tracking may find this helpful.
Breaking down tracking purposes
Imagine your usual smartphone morning routine. You open your favourite newspaper app. Content loads from the newspaper's servers and external sources. In a few seconds the page has fully loaded. However, the tracking just got started.
Analytical trackers measure how much time you spend on the homepage and where you go next. Ad performance trackers confirm banner ads are shown and eagerly await any taps. A recommendations widget suggests articles based on your reading history. This session illustrates five overarching tracking purposes.
- 🔩 Essential: Ensure core functionality and safe user experiences. Examples: Bot detection, application performance monitoring.
- 📊 Analytical: Gather insights about content and usage. Examples: Usage statistics, audience measurement,
- 📰 Personalization: Tailor content and user experiences. Examples: Content recommendations, product suggestions.
- 🧲 Advertising: Profile users and serve contextual or profile-based ads. Examples: Behavioural ads, direct marketing banners , ad performance measurement
- 🤝 Social media: Track interactions with embedded social media posts. Examples: Track post views and comments
Interpreting trackers
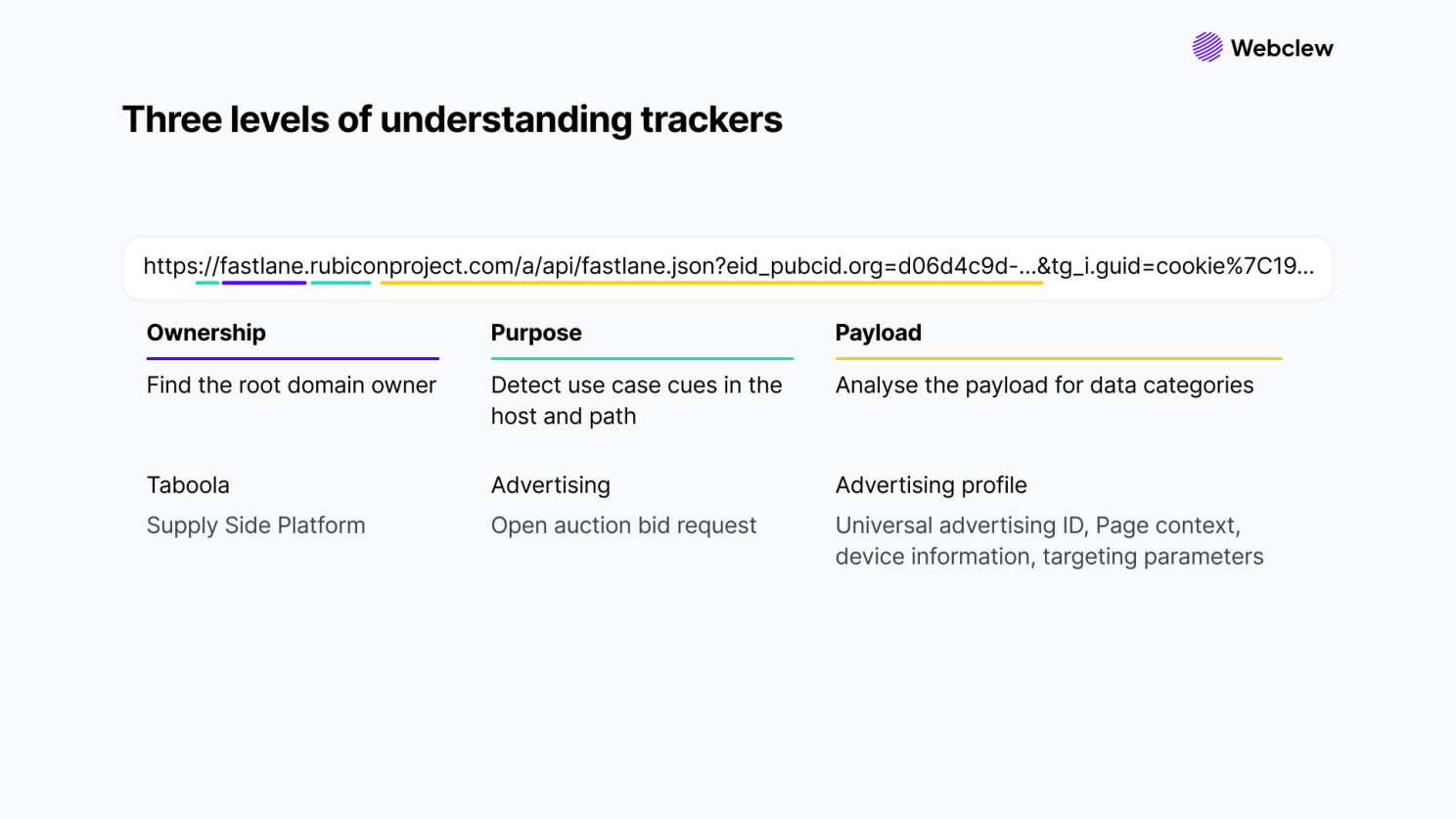
Understanding a tracker requires some detective work. Your first clue? The root domain. This domain usually maps directly to a specific vendor and therefore anchors the tracker’s purpose. For example, google-analytics.com clearly maps to the Google Analytics service and an analytical purpose.
After Google announced the third-party cookie phase-out, which it now abandoned, service providers started masking third-party domains as first-party (CNAME cloaking). For instance, tracking.example.com could point to analytics.thirdparty.com.
Intuitively, purpose attribution is a proxy for risk. Third-party ad tracking often appears more intrusive than a first-party analytics tracker. Yet the ad tracker might detect click fraud, while the analytical tracker could be feeding a direct marketing engine with unlawful or disproportional user profiling.
To really understand what a tracker does, dig deeper on two levels:
1/ Look for keywords in the host or path (e.g., /track/, /collect/) signaling the use case.
2/ Scan the query string and request body for data types such as user IDs, device info, or location.
Together, a tracker’s root domain, URL structure, and payload reveal its vendor, purpose, and data collection.
All you need to get started is a proxy server, a network analysis tool such as Wireshark, and a good chunk of time to sift through HTTP requests and technical documentation. The pain is often worth it. Even a single spot check can often uncover hidden or unauthorized tracking.
To bring order to the chaos, and separate the helpful from the harmful, I developed the Tracking Intrusiveness Score (TIS). It measures three key drivers of intrusiveness on a five-point scale:
- Identity: Persistence and linkability of a user identifier;
- Insights: Depth and sensitivity of attributes collected; and
- Use case: Privacy impact based on the tracking usage.
![]()
Evaluating tracking intrusiveness: Trackers, in their full detail, can be overwhelming. A single tracker often triggers multiple API calls, each stuffed with dozens of parameters. Payload naming conventions vary wildly. The parameter ‘pid’ can mean personal ID for one and publisher ID for the other.
For simplicity, I define the TIS on a 10-point scale, calculated as the average of the three drivers multiplied by two.
Let’s look at two different requests from the same ad tech provider Taboola to illustrate how TIS can vary.
Request https://am-vid-events.taboola.com/st tracks video ad events to generate aggregated performance metrics. The payload includes campaign and video identifiers, yet no user IDs, along with device metadata. The TIS is only 2.7 (ID 1, IN 2, UC 1).
In contrast, request https://display.bidder.taboola.com/OpenRTB/TaboolaHB/auction is part of an open auction bid. This request includes a persistent advertising ID, detailed device information (e.g., screen size, language), and context about the page and ad slot. These elements yield a much higher TIS of 7.3 (ID 4, IN 3, UC 4).
Applying the Tracking Intrusiveness Score These categories and scales help me untangle the clew of endpoints and payload parameters. I encourage you to apply the TIS for common trackers for your organization and answer three questions:
- Risk prioritization: Which trackers pose the highest intrinsic risk?
- Control alignment: Do data protection measures and vendor due diligence efforts match each tracker’s intrusiveness?
- Data minimisation: Can you meet your data strategy with less intrusive tracking?
Online service providers tend to manage familiar trackers closely and turn a blind eye to those that are harder to interpret. TIS helps surface blind spots, prioritize tracking controls, and align privacy resources with actual risk.
Give it a go and do share your feedback or suggestions.